Zelfstandige datasets, die oorspronkelijk bij een transactiesysteem hoorden, worden steeds vaker onderdeel van een grotere, gecombineerde dataset. Om waardevolle informatie te kunnen genereren, wordt data uit diverse bronnen samengevoegd, geanalyseerd en getoetst aan normen en regels. Dit proces stelt organisaties in staat hun waardecreatie te realiseren door antwoorden te vinden op cruciale vragen, zoals welke producten gepromoot moeten worden, welke relaties benaderd moeten worden, wanneer tot actie moet worden overgegaan en hoe het hoogste rendement behaald kan worden.

Uitdagingen bij het Samenvoegen van Datasets
Het samenbrengen van datasets kent diverse uitdagingen, waarvan de totstandkoming van een complete en consistente dataset er een is. Zo is het niet zomaar mogelijk om aantallen in stuks, dozen en pallets op te tellen om een totaalaantal te verkrijgen. Evenzo vereist een waardebepaling van bezittingen in verschillende continenten, zoals Azië, Europa en Amerika, meer dan louter optellen; er moet rekening gehouden worden met de geldende valuta.
Het geautomatiseerd bepalen van doorlooptijden voor processen die verschillende datum-notaties hanteren, vereist eerst een datum-conversie. In tegenstelling tot mensen, kan een computer deze omzetting niet impliciet uitvoeren, maar moet hiervoor expliciet geïnstrueerd worden.
De verschijningsvorm van de data, de datastructuur (relaties) en de syntax (eenheden en schrijfwijze) worden bepaald door de bron. Verschillende bronnen hebben verschillende verschijningsvormen. Door de structuur van de bron en de verschijningsvorm van de data-elementen te kennen, kunnen deze worden ingelezen en, waar nodig, worden omgezet naar de vereiste structuur en verschijningsvorm.
Enkelvoudige Transformaties
Het omzetten van een structuur is relatief eenvoudig wanneer het gaat om een enkelvoudig data-element en de registratie ervan. De datum '23 januari 2020' kan bijvoorbeeld eenvoudig worden omgezet naar '23-01-2020' of '01/23/20'. Dit wordt aangeduid als een enkelvoudige transformatie.
Nadelen van Handmatige Transformaties
In de praktijk worden vaak handmatige, op Excel gebaseerde transformatieprocessen toegepast. Dit is vanuit architectuurperspectief echter geen structurele oplossing. Een op Excel gebaseerde transformatie is arbeidsintensief, persoonsafhankelijk, tijdrovend en foutgevoelig.
De Rol van ETL en Data Warehousing
Om data correct, snel en betrouwbaar vanuit een bron over te zetten naar een doelsysteem waar data gecombineerd wordt, is een geautomatiseerde transformatie vereist. Het inzetten van een gespecialiseerde tool beperkt de menselijke factor tot de initiële inrichting, waarna het proces herhaald en betrouwbaar uitgevoerd kan worden. Dit gehele proces wordt aangeduid als een ETL-proces.
Wat is ETL?
- Extract: Het uitlezen van de data uit de bron.
- Transform: Het uitvoeren van de transformatie van de bronsstructuur naar de doelstructuur.
- Load: Het opslaan van het resultaat in het doelsysteem.
Het Data Warehouse (DWH)
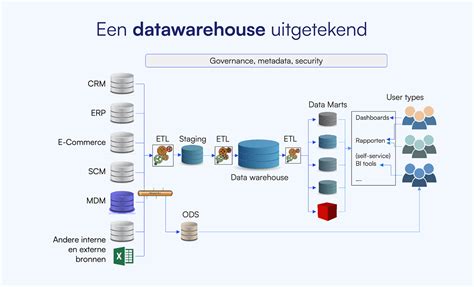
Het samenvoegen van verschillende datasets tot één grote dataset vereist een grote database waarin het resultaat kan worden opgeslagen. Hier ontstaat een totaalbeeld van de data waarover een organisatie beschikt, vaak inclusief historie. Deze dataverzamelplaats in een database wordt een datawarehouse (DWH) genoemd. Het datawarehouse vertegenwoordigt de Singel Point Of Truth (SPOT).
Een datawarehouse is een systeem voor het verzamelen, organiseren, opslaan en ter beschikking stellen van data, typisch gebruikt voor beslissingsondersteuning en business intelligence (BI) doeleinden.
Verschillende Datawarehouse Modellen
Er zijn diverse methoden voor het opzetten van een datawarehouse:
- De Bill Inmon methode, die ook wordt toegepast in operationele systemen.
- De methode van Ralph Kimball, ook bekend als het sterschema.
- De datavault-methode van Dan Linstedt, die elementen van zowel de Inmon- als de Kimball-methode combineert.
De methoden van Bill Inmon en Ralph Kimball bestaan naast elkaar en vullen elkaar aan.
Componenten en Implementatie van een Datawarehouse
Een datawarehouse bestaat uit verschillende componenten. Het begint met het ontsluiten van bronnen, waarna datamarts worden gemaakt via een data flow. Deze datamarts kunnen vervolgens worden ontsloten door software als Power BI. Dit is het zichtbare deel van het datawarehouse; alle onderliggende componenten moeten doordacht zijn voor een toekomstvaste data-architectuur.
Stappenplan voor Datawarehouse Implementatie
Het opzetten van een datawarehouse is een uitgebreid en complex project dat een bepaalde volwassenheid van de organisatie vereist. Een gestructureerde aanpak kan bestaan uit de volgende stappen:
- In kaart brengen van informatiebehoeften: Deze behoefte moet in lijn zijn met de strategische doelstellingen van de organisatie.
- Identificeren van databronnen: Nagaan welke gegevensbronnen nodig zijn en of er mogelijk nieuwe bronnen gecreëerd moeten worden, met aandacht voor de aard van de data en privacywetgeving (AVG).
- Ontwikkelen van een routekaart: Vaststellen welke zaken als eerste worden opgepakt, met nadruk op wendbaarheid en het vermijden van het voorafgaand verzamelen van alle data. Een 'snelspoor'-benadering kan worden overwogen voor urgente behoeften.
- Kiezen van datawarehouse architectuur en technologie: Selecteren van geschikte modelleringstechnieken en bepalen van de benodigde lagen (bijvoorbeeld een drielagenmodel).
- Daadwerkelijke implementatie: Opleveren van de verschillende lagen en tussenstappen gedurende het traject, met als eindresultaat rapportages of dashboards voor de eindgebruiker.
Ondersteunende Processen en Beveiliging
Naast de technische implementatie is het cruciaal om de ondersteunende processen rondom het datawarehouse in te richten. Dit omvat ook het waarborgen van de beveiliging van de omgeving en de data, zowel voor beheerders als voor alle medewerkers, bijvoorbeeld door middel van een autorisatiematrix.
Het datawarehouse moet een integraal onderdeel worden van de dagelijkse bedrijfsprocessen, gerealiseerd door inzet van data stewards en data engineering.
Continue evaluatie van het datawarehouse op basis van verzamelde inzichten en feedback van gebruikers is essentieel om aanpassingen te kunnen doen waar nodig. Daarnaast dient er een duidelijk proces te zijn voor het gebruik van data uit het datawarehouse voor data science projecten.
Data Ontsluiten: Van Bron naar Inzicht
Het ontsluiten van databronnen is de cruciale eerste stap voor datagedreven werken. Dit proces omvat het verzamelen en voorbereiden van ruwe gegevens, zodat deze waardevolle inzichten kunnen opleveren. Het gaat niet alleen om het verzamelen, maar ook om het begrijpen van de context van de data, wat essentieel is voor nauwkeurige conclusies, het bepalen van de relevantie van data, en het opstellen van duidelijke rapportages.

Soorten Databronnen en Hun Complexiteit
Het ontsluiten van databronnen varieert in complexiteit. Een eenvoudige lijst of tabel met kolommen en rijen is relatief makkelijk in te lezen. Complexer wordt het wanneer er met genormaliseerde tabellen gewerkt wordt, waarbij data in meer tabellen is opgesplitst om redundantie te voorkomen. Hoe meer tabellen en hoe minder documentatie, hoe uitdagender het kan zijn om de benodigde gegevens te achterhalen.
JSON-bestanden, met hun gestructureerde, vaak hiërarchische data, kunnen lastig zijn voor sommige tools. API's, hoewel niet per definitie moeilijk, vereisen vaak complexere authenticatieprocessen (zoals OAuth2) en omgang met tokens. Optionele elementen in JSON- en XML-documenten en variërende structuren van API's kunnen de verwerking bemoeilijken.
Moeilijke Databronnen
Een databron wordt als 'moeilijk' beschouwd wanneer de structuur niet direct geschikt is voor analyse. Dit kan komen door:
- Genormaliseerde tabellen met onlogische relaties.
- Technische formaten zoals JSON.
- Beperkingen vanuit API's, zoals authenticatie, paginering en limieten.
Key-value databases en JSON-structuren zijn technisch flexibel, maar analytisch onhandig. Ze moeten eerst worden omgezet naar vaste kolommen en relaties om bruikbaar te zijn in dashboards.
Oplossingen voor Complexe Databronnen
Organisaties kunnen hulp inschakelen voor het ontsluiten van complexe databronnen, zoals API's, ERP-systemen, CRM-pakketten en maatwerkdatabases. Hierbij ligt de focus niet alleen op de techniek, maar vooral op het betrouwbaar en analyseerbaar maken van de data.
Data Warehousing Modellen en Technieken
Er zijn verschillende manieren om data in een datawarehouse te zetten. Naast ETL (Extract, Transform, Load) bestaan er ook data imports en data loads. ETL-processen kunnen ook worden gebouwd met scripts.
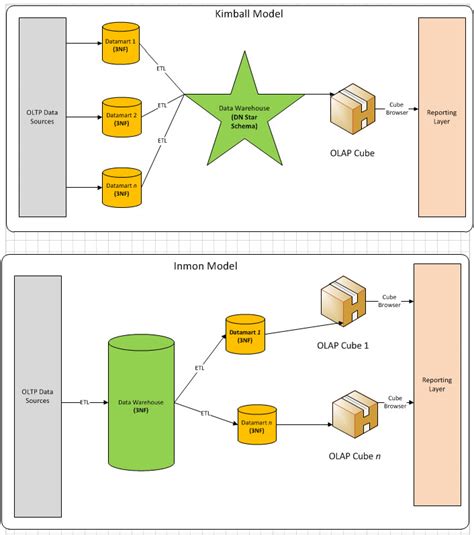
Inmon vs. Kimball
De Bill Inmon methode, gebaseerd op datanormalisatie, slaat data nooit dubbel op. Dit resulteert in een model met veel tabellen, wat voor analyse soms minder direct bruikbaar is. Het sterschema van Ralph Kimball is een beperkte vorm van normalisatie, met een centrale feitentabel rondom dimensietabellen. Een sneeuwvlokschema is een verdere uitwerking hiervan.
De datavault-methode van Dan Linstedt gebruikt kernbegrippen als hubs, links en satellites voor een slimme opslag van ruwe data.
Keuze van Modelleringstechniek
De keuze voor een modelleringstechniek hangt af van de bron van de data:
- Bij data uit een relationele database is het raadzaam zo dicht mogelijk bij de oorspronkelijke structuur te blijven.
- Data uit een API kan een specifieke focus hebben en vereist mogelijk een andere aanpak.
Het is belangrijk om een overzicht te maken van wat er met de data uit een bron gedaan kan worden, met focus op 'quick wins' en middellange- tot lange-termijn projecten.
Data Lakes en ACID-principes
In tegenstelling tot een datawarehouse, waar met ACID (Atomic, Consistent, Isolated, Durable) gewerkt wordt om de integriteit van de database te garanderen, ontbreekt dit bij een data lake. Een data lake wordt vaak gebruikt voor dataopslag en -verwerking, maar een datawarehouse biedt meer garantie op dataintegriteit en betrouwbaarheid.
SQL en Moderne Data-analyse
In een datawarehouse omgeving is SQL vaak de standaardtaal voor datamanipulatie. De vele standaardisaties maken het makkelijk om met SQL te werken, en deze is uitwisselbaar tussen verschillende databaseomgevingen. Er is een trend gaande om met SQL ook ongestructureerde data te benaderen, ondersteund door libraries in Python en R.
Succesfactoren en Evaluatie
Het succes van een datawarehouse-implementatie hangt af van diverse factoren. Naast de technische aspecten, is het cruciaal om de informatiebehoeften van de organisatie te begrijpen en deze te koppelen aan strategische doelstellingen.
KPI's voor Succesmeting
Het meten van het succes van een implementatie kan uitdagend zijn, zeker omdat wensen en eisen tijdens het proces kunnen veranderen. Toch is het belangrijk om te proberen het succes meetbaar te maken met behulp van Key Performance Indicators (KPI's), bijvoorbeeld:
- Voldoen aan de afgesproken tijd en budget.
- Voldoen aan de oorspronkelijke eisen en doelstellingen.
- Tevredenheid van gebruikers met het systeem en de begeleiding.
Gebruikersbetrokkenheid en Data Stewardship
Het vinden van fouten tijdens het testen kan een indicatie zijn van de betrokkenheid van medewerkers. Het aantal betrokken medewerkers en de beschikbare tijd voor het implementatietraject zijn eveneens belangrijke factoren.
Het inzetten van een data steward en data engineering helpt om het datawarehouse een onderdeel te maken van de dagelijkse bedrijfsprocessen.
Toekomstige Trends en Cloud Oplossingen
De laatste jaren is er een verschuiving te zien naar het opslaan van datawarehouses in de Cloud. Hybride oplossingen, waarbij organisaties hun eigen omgeving opzetten bij publieke cloudproviders zoals Microsoft Azure of Amazon AWS, komen ook steeds vaker voor.
De trend om datawarehouses en data lakes samen te voegen, en de snelle ontwikkelingen op dit gebied, maken het soms lastig om verschillende onderdelen goed te scheiden. Hierdoor verwordt het datawarehouse steeds meer tot een algemene term voor alles wat met data en analyse te maken heeft.
Data Ontsluiten voor Specifieke Sectoren
Data2Care biedt bijvoorbeeld volledige datawarehouse oplossingen voor zorginstellingen, met een focus op het ontsluiten van data via Power BI, gebruikmakend van de ster-schema methodiek van Kimball en de basisprincipes van ETL.
Bij het ontsluiten van data is privacy van groot belang. Bedrijven moeten transparant zijn over welke gegevens ze verzamelen, waarom, en hoe ze deze gebruiken, en zorgen voor veilige opslag en toegangsbeheer.
Visueel Maken van Data
Nadat de gegevens zijn ontsluit en opgeslagen in een datawarehouse, kunnen ze worden getransformeerd en omgezet naar visuele dashboards met behulp van Business Intelligence (BI) tools. Power BI van Microsoft is hierbij een veelgebruikte tool.
Het doel is om data om te zetten in bruikbare informatie, zodat organisaties betere, datagedreven beslissingen kunnen nemen, patronen kunnen herkennen, processen kunnen optimaliseren en de concurrentie voor kunnen blijven.
Data Warehouse & Report tutorial using Power BI
tags: #ontsluiten #informatie #datawarehouse